Accessors vs Dirty-checking in Javascript Frameworks
One of the many ways in which EmberJS, AngularJS, and BackboneJS differ is in how they treat their models. AngularJS uses dirty checking on Plain Old Javascript Objects (POJSO); whereas EmberJS and BackboneJS both use accessors (getters and setters) on wrapped objects.
We will be exploring the ways in which these two approaches differ, and the implications these differences have when it comes to choosing which Javascript framework we we should write our single page apps in.
The Basics permalink
Models are one of the fundamental tenets of an MV* architecture. They are the basic building blocks where information about various object states get stored and retrieved form. Most Javascript frameworks for front end user interfaces used to build single page applications (SPAs) use MV* architectures, and a feature that most of them have in common is the ability for the View to update the Model, and for the Model to update the View.
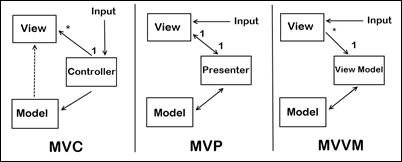
For this to happen, there needs to be to be a means to “listen” for these changes, and then trigger some code to respond to that change. Depending on which flavour of MV* architecture the framework uses, these may use a Controller, ViewModel, or Presenter as a conduit. Leaving the middleman out, we have:
- When a change occurs in an input field in a form, the object modelling that form should be updated.
- a change in the View
-->response triggered in the Model
- a change in the View
- When a change occurs in the object modelling that form (perhaps as a result of a sync via AJAX), the corresponding fields in the form should be updated.
- a change in the Model
-->response triggered in the View
- a change in the Model
With MV* frameworks like EmberJS and AngularJS, you get this out of the box - you only need to declaratively specify which models are linked to which views - and they call this “Two-way Data Binding”.
With other MV* frameworks like BackboneJS, you get this too, but a significant amount of manual “wiring” is required - you have to set up the listeners in both directions yourself.
In order for this to work under the hood, the framework will need a way to “observe” for changes of Models. This post will explore two methods that Javascript MV* frameworks use to listen for changes on Models.
Note that we will not be exploring how Javascript MV* frameworks listen for changes in Views in this post, as essentially. They are for the most part wrappers around EventTarget.addEventListener, and are thus not quite as interesting.
Listeners and Digest Cycles permalink
Implementations of listeners and of digest cycles are separate, but closely related. When a listener on any change gets fired, the code that it triggers is by default run immediately.
However, for a number of reasons, performance being the main one, the framework may instead queue these listeners. This framework would also perform digest cycles, which are, simply put, code that runs at a set time interval. In each of these digest cycles, the triggers of the listeners in the queue are all run at once.
Using POJSO permalink
Using Plain Old Javascript Objects makes for code that has very simple syntax, and thus is easier to write. With dirty checking, no special syntax is required - simply change the properties of an object, and it “magically” triggers the required listeners.
(Behind the scenes, the framework runs a digest cycle, and during each one, it performs a dirty check, which is a deep comparison on all the Models that are presently displayed within the View. If a difference is detected, and a listener is attached to that difference, it is triggered.)
Using accessors, on the other hand, implies two additional things, which add to, and thus complicate the syntax.
Firstly, you would need to make all of your objects within the Model wrapper classes provided by the framework, e.g.:
var Book = Backbone.Model.extend({ /* ... */ });
var myBook = new Book( /* … */ );
Secondly, in order to trigger the listeners correctly, you would need to remember to use gets and sets whenever using its properties, e.g.:
myBook.set({title: 'Qryq - Stop RESTing and use queues instead'}); //triggers listeners
myBook.attributes.title = ‘Qryq - Stop RESTing and use queues instead’; //does NOT trigger listeners
Computed properties permalink
Being able to define a property as being computed from a number of others is a particularly nifty feature of EmbersJS, and made possible because of its use of accessors. 2
App.Person = Ember.Object.extend({
bmi: function() {
var height = this.get(‘height’);
return this.get(‘weight’) / height / height;
}.property(‘weight’, ‘height’)
});
In the above code, we are creating a model which has a property named bmi. This property is bound to the weight and height properties of the object - and we do not need to cache it, or recompute it each time we use it.
Betrand Meyer’s Uniform Access Principle states that “all services offered by a module should be available through a uniform notation, which does not betray whether they are implemented through storage or through computation.” Computed properties, implemented in the manner that EmberJS has, are one way of implementing properties observing this principle. Bertrand goes on to name a number of benefits this yields. The main benefit, in my opinion, is that it gives the developer one less thing to have to manage, and thus have to worry about.
Performance permalink
Performance is a particularly tricky issue to tackle.
On the surface, it would appear that dirty checking would consume more memory and processor cycles than event listeners. The reason for this is straight forward: There is no need to check for differences in each cycle. When you are doing this at a very high frequency, which happens if you have a large number of objects, responsiveness starts to take a hit.
However, this issue not so straightforward - Misko Hevery, creator of AngularJS, makes some good points on this, in his S/O answer on AngularJS data binding. Essentially, dirty checking is “fast enough” for most user interfaces:
"So the real question is this: can you do 2000 comparisons in 50 ms even on slow browsers? That means that you have 25 µs per comparison. I believe this is not an issue even on slow browsers these days. There is a caveat: the comparisons need to be simple to fit into 25 µs."
— Misko Hevery
Thus we need to ensure that all comparisons are not slower than this threshold. In practice, more complex models with computed properties are an eventuality, and a comparison during a dirty check of such computed properties is likely to exceed this threshold. When enough of these objects are present, the lag during digest cycles (occurring between each render) will bring down the frame rate, and at some point begin to become noticeable to the human eye - so be prepared to cache these more complex model states, and to handle their state changes manually.
Digest cycles with accessors permalink
I disagree with Misko, however, on his other points that change coalescence cannot happen using accessors; and that change listeners need to fire immediately using accessors. Indeed, these are features that would be lacking in basic implementations of non-dirty checking based change listeners.
However, do note my earlier point about the implementations of change listeners, and the implementations of digest cycles being separate, but related. When using dirty checking, a digest cycle implementation is compulsory - you have to poll for changes at an interval. When using accessors, a digest cycle is optional; however, digest cycles are certainly not mutually exclusive to dirty checking.
A good real world example of a Javascript framework that combines accessors with digest cycles is EmberJS. EmberJS uses accessors to aggregate change listeners, and trigger them only once per digest cycle. It does not, however, implement change coalescence - and this is genuinely much trickier to achieve using accessors compared to using dirty checking, but it should be possible 3.
Adding some metrics permalink
The issue of performance is very much still an open debate. It is likely that using accessors will outperform dirty checking in some apps, but observe a reversal in performance in other apps. Ideally, one should try both out, and see which works better. If you do not have the time to implement your app using multiple frameworks to test this hypothesis for your particular app - and I suspect that this will be the case for most of us - then you could make an educated guess as to which approach will yield the better performance based on answers to the following questions:
- Will you be using many computed properties?
- If so, will you be willing to cache model states and handle state changes manually?
- Threshold: ~25 µs per “piece of information”
- Will you have many models bound to views?
- If so, will you have many views rendered on the screen at once?
- Threshold: ~2000 “pieces of information”
- Are you targeting mobile devices for your app?
- If so, adjust the thresholds above as appropriate
Misko does not define what he means by a piece of information. So here is one possible method:
- Each Javascript primitive (i.e. a
String, aNumber, or aBoolean) would count as one piece of information. - For
Objects andArrays, one simply counts the total number of primitives contained within, plus one for itself.- This is necessary because not all model states take an equal amount of time to compare; some may even take an order of magnitiude longer than others.
- e.g.
{name:'Bob', weight:80, height:200, foo:[true, false]}—> 1Object, 1Array, 5 primitives —> 7 pieces of information
Of course, this metric is only intended to be a rough gauge. Different measures or definitions of what constitutes pieces of information, are valid, as long as the same one is consistently applied to all models. What is more important here, is to anticipate and plan for for future increases in model complexity.
If it is not possible to estimate or anticipate the (future) complexity of your models at this stage, you could treat the point on performance as a case of something where the verdict is still out, and instead base your decision on the other points of difference.
Future proofing permalink
Future editions of ECMAScript may potentially allow listeners to be set directly on POJSO. This is already in the works with w3c’s object binding proposal, and TC39’s Object.observe/video. In fact Google Chrome has already implemented the latter.
That will remove the necessity for both accessors and dirty checking, as frameworks will most likely be reimplemented to use this to take advantage of native execution over interpreted execution for listening to changes on Models. This will mean that if you have written your app using a Javascript framework that uses dirty checking like AngularJS, your code will not need to change at all. However, if you have written your app using a Javascript framework that uses accessors like EmberJS or BackboneJS, you will need to refactor your code1 in order to gain the extra performance.
(Of course, it is the other way around for the authors of the Javascript frameworks. A dirty checking framework will need to do a more complex refactor to switch to using listeners on POJSOs instead of dirty checks in each digest cycle, compared to an accessor based framework.)
Conclusion permalink
Yehuda Katz spoke recently about EmberJS at MelbJS 4. At the end of his talk, he mentioned that he was on the board of ecmascript.org, stating that one of the proposals that he was passionate about and was promoting, was being able to set listeners natively on POJSO objects. (proposal linked above, under the “Future Proofing” section).
These are nifty and would allow Javascript frameworks to leverage the best of both worlds with regards to the main points of differentiation between accessors and dirty checking that we have explored in this post.
Unfortunately, ES6 is not coming out for a while yet. The proposal to implement these features has yet to be accepted for inclusion into ES6, so it may take even longer.
Thus I began to think about how the Javascript frameworks that are out there today have tackled this problem - in particular BackboneJS, AngularJS, and EmberJS. How have these issues been addressed here and now?
There has not been much written about this, so I have put this this rather small, and often overlooked, aspect of Javascript frameworks under a magnifying glass.
Picking a Javascript single page application framework is difficult, and hopefully I have given you one more set of considerations to mull over in picking one.
tl;dr permalink
- Dirty checking
- Pros
- Easier syntax when using POJSO
- Code refactor not required with next ECMAScript
- Cons
- Need to set up own cache & listeners
- Unsuitable for high frequency callbacks/ large number of models
- Pros
- Accessors
- Pros
- Allows computed properties
- Avoid excessive
null/undefinedchecks on models
- Cons
- More verbose syntax
- Pros
- Performance: ?
Footnotes:
1 Not a very complicated one. Should be accomplishable using some nifty greps and seds
2 I do not see any reason why it cannot also be accomplished using dirty checking, however, I have yet to see this combination implemented in a SPA framework.
3 Personal conjecture only here. Again, I have yet to come across an implementation of this in a SPA framework. Someone would have to do it first, before we make a judgment as to whether this is more efficient than dirty checking. Change coalescence over POJSOs based upon Object.observe has already been done, so it could just be a matter of time.
4 Shameless plug: I will be speaking about qryq at the next MelbJS